Contribución del invitado: “Detección de recesión a lo largo de la frontera de las expectativas”

Hoy tuvimos la suerte de presentar una publicación invitada escrita por Pascal Michaillat (UCSC).
¿Está la recesión de los Estados Unidos en una recesión? A pesar del retraso de los debates y los anuncios oficiales de los economistas, he desarrollado un nuevo algoritmo basado en un análisis sistemático de los datos del mercado laboral, pero a partir de mayo de 2025, la economía estadounidense está en una recesión del 71%. La recesión puede haber comenzado a fines de 2023 o mediados de 2014.
Las pruebas oportunas de recesión son cruciales para una respuesta de política efectiva, pero la declaración oficial del Comité de Ciclo de Empresas NBER a menudo llega dentro de un año posterior al comienzo de la recesión. Curiosamente, con el tiempo, la página web de NBER destacó la tasa de desempleo en los Estados Unidos, pero la explicación que determina la fecha de recesión no menciona que el comité de citas usa la tasa de desempleo por completo. Este retraso no es práctico para los responsables políticos, las empresas y las familias que necesitan tomar decisiones en tiempo real. Pero, al igual que las reglas SAHM, los indicadores existentes en tiempo real que rastrean las tasas de desempleo proporcionan valiosas señales tempranas.
Sin embargo, el SAHM y las reglas relacionadas se basan en mediciones individuales y a veces ruidosas de la economía. El algoritmo se basa en información, que combinar datos del mercado laboral creará una señal ruidosa y poderosa. En trabajos anteriores con Emmanuel Saez, desarrollamos una regla que combina datos de desempleo y vacantes para detectar la recesión más rápido y más firmemente que los indicadores basados solo en el desempleo. La base de este trabajo es la curva de Beveridge: al comienzo de cada recesión, el desempleo ha aumentado considerablemente a medida que caen las aperturas de trabajo.
El nuevo algoritmo toma el siguiente paso lógico: en lugar de filtrar y combinar datos con una fórmula específica, busca sistemáticamente el mejor enfoque. El objetivo es encontrar la mejor oportunidad para ver estos datos.
El algoritmo primero genera millones de potenciales clasificadores de recesión, cada procesamiento de datos de desempleo y vacantes de una manera única y utilizando umbrales de recesión únicos. El algoritmo realiza una prueba simple pero exigente para él: para sobrevivir, el clasificador debe identificar las 15 recesiones de 1929 a 2021 sin un solo falso positivo. Esta prueba nos da más de 2 millones de clasificadores históricamente perfectos.
Tener millones de clasificadores perfectos trae un nuevo desafío: ¿cuál elegir? Para resolver este problema, el algoritmo evalúa los clasificadores en dos dimensiones clave: cómo detectan la recesión (esperada) temprano y la consistencia (precisión) de esa señal. Al trazar la desviación estándar del retraso de detección promedio versus el retraso de detección para cada clasificador, el algoritmo determina los límites fronterizos esperados, un conjunto de clasificadores de élite que proporcionan la mejor compensación entre la velocidad y la precisión. Para cualquier precisión dada, ningún clasificador es más rápido que el clasificador en ese límite. Luego, desde este borde, el algoritmo selecciona una colección de 7 mejores artistas. Estos son todos clasificadores cuya desviación estándar del retraso de detección es inferior a 3 meses, lo que garantiza que el ancho del intervalo de confianza del 95% de la fecha de inicio de recesión estimada sea inferior a 1 año.
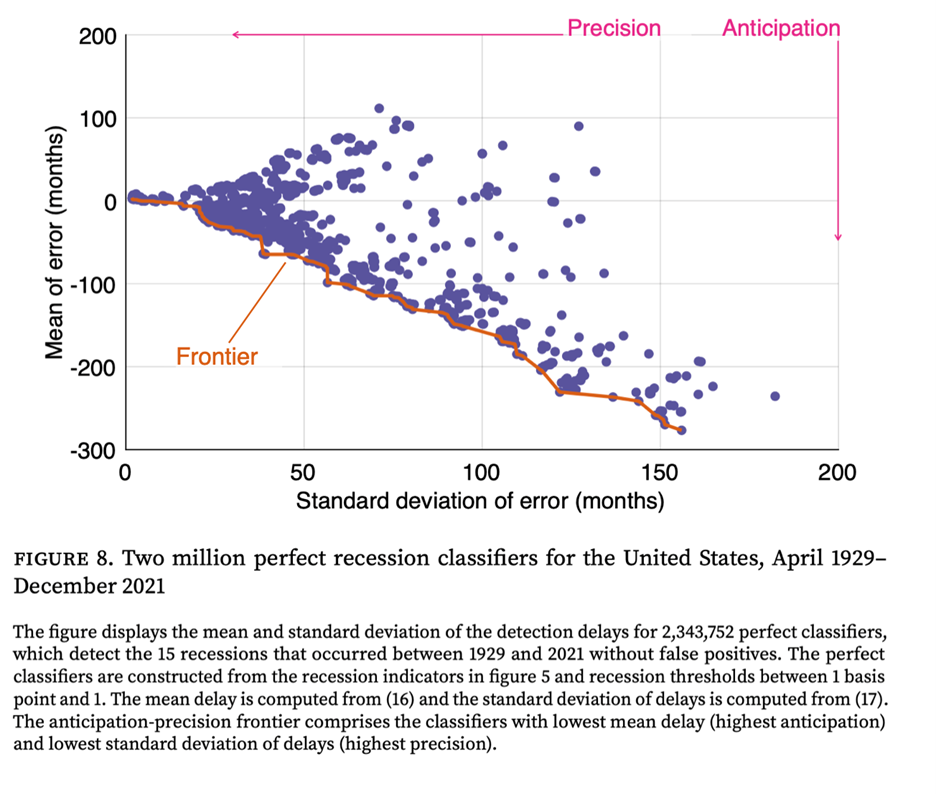
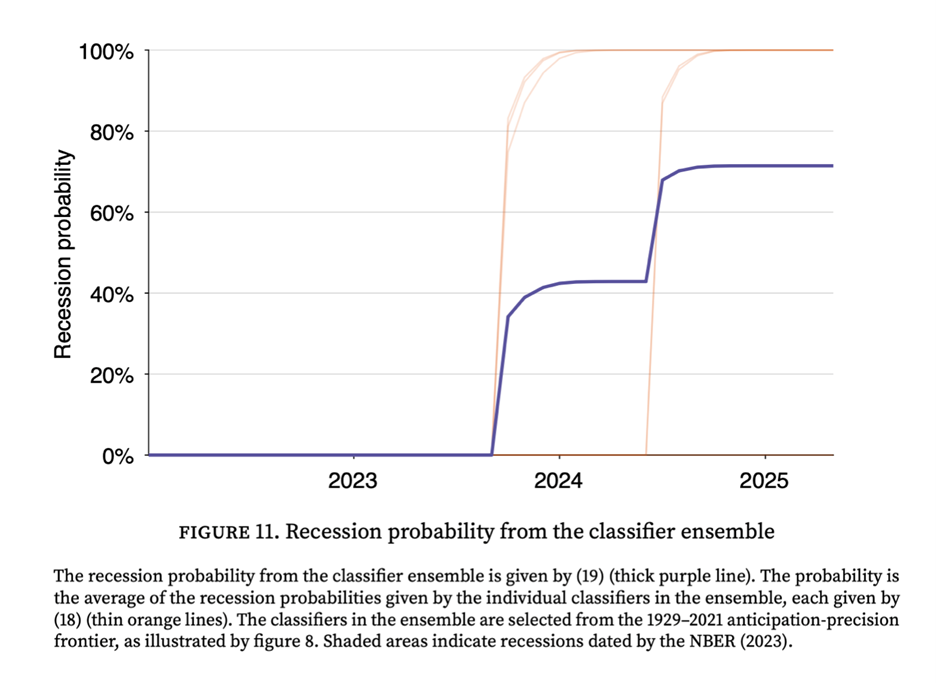
Este conjunto de clasificadores proporciona una probabilidad en tiempo real de disminución. En cada recesión histórica desde 1929, la probabilidad ha aumentado bruscamente cerca de un comienzo lento y permaneció alta hasta el final. Cuando apliqué el modelo a los últimos datos, dijo que la probabilidad de una recesión se había disparado al 71% a partir de mayo de 2025. Esta no es una abstracción estadística. Este es un resultado directo del debilitamiento del mercado laboral. Desde mediados de 2022, la combinación de desempleo creciente y vacante descendente desencadenó cinco de los 7 clasificadores en el conjunto, aumentando la probabilidad de una recesión. La probabilidad de una recesión se volvió positiva por primera vez a fines de 2023, cuando se activaron 3 de los 7 clasificadores. La recesión aumentó aún más a mediados de 2014, cuando se activaron 2 clasificadores. Actualmente, solo 2 de los 7 clasificadores en el conjunto han sido inactivados.
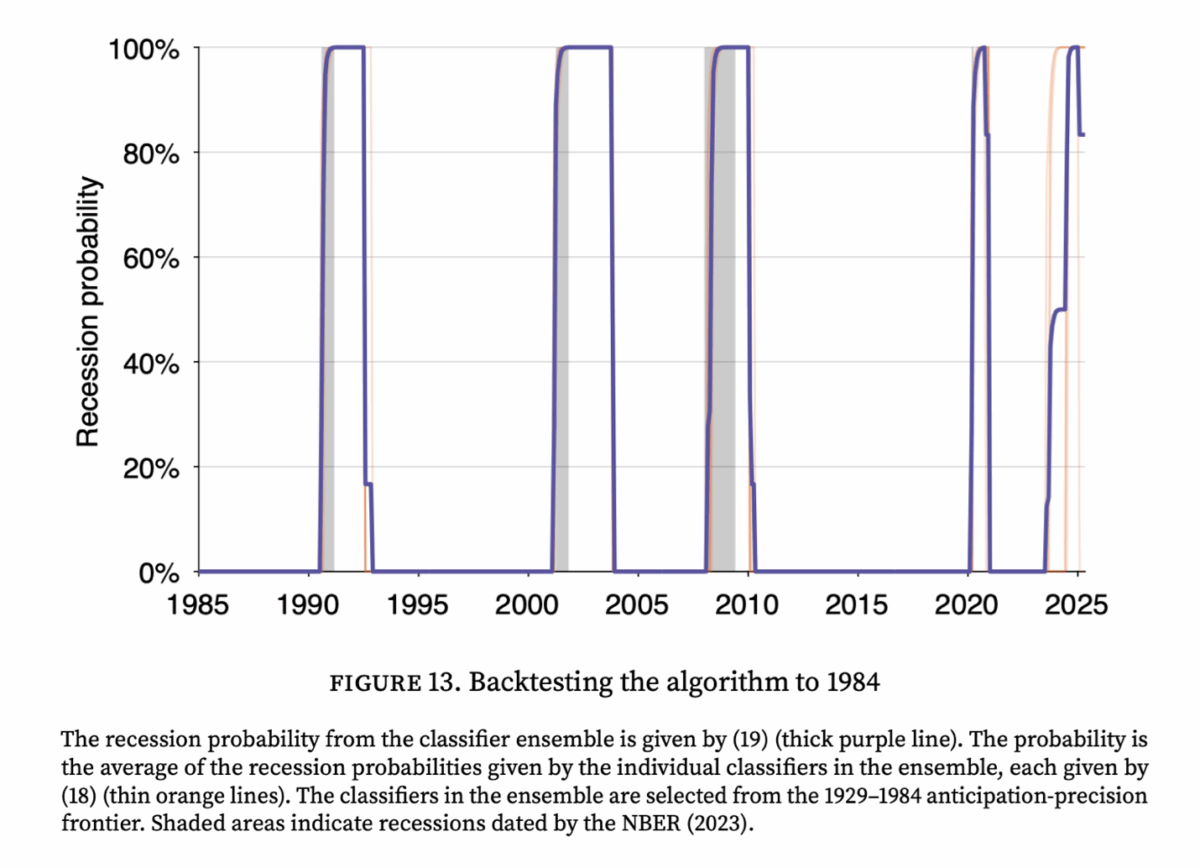
Para verificar la fiabilidad del modelo, realicé una serie de pruebas de retroceso. Por ejemplo, solo entrené el algoritmo usando datos a diciembre de 1984 y le pedí que detectara todas las recesiones posteriores. Todos los clasificadores en el conjunto construido por los datos de 1984 hicieron un buen trabajo identificando correctamente las cuatro recesiones durante el período de prueba 1985-2021, incluida la caída de Internet y la enorme recesión, sin ningún falso positivo. Lo más impresionante, incluso sin ver ningún dato del pasado 1984, el conjunto del clasificador descubrió la gran recesión de manera oportuna, con la probabilidad de que su recesión se elevara en el verano de 2008 y proporcionó una advertencia clara y oportuna. De hecho, el rendimiento del algoritmo fue sorprendente durante todo el período de prueba de 1985 a 2021. Entre las cuatro recesiones durante el período de prueba, la desviación estándar del retraso fue de solo 1,4 meses, y el retraso promedio fue de solo 1,2 meses. Los datos del conjunto del clasificador capacitados en 1929 – 1984 asignaron una probabilidad de recesión del 83% a los datos actuales (5 de los 6 clasificadores en el conjunto se activan actualmente).
En general, este nuevo algoritmo muestra que el mercado laboral está enviando una señal clara: las condiciones para una recesión no están dentro del rango, ya están aquí. Si resulta que, una vez que el polvo se asienta, la economía de los Estados Unidos no caerá en la recesión: ¿qué aprenderemos? En este caso, el algoritmo se puede volver a entrenar en los nuevos datos y el clasificador que detecta erróneamente la recesión será eliminada. Sin embargo, dado que muchos clasificadores en la frontera indican una recesión, se espera que los límites de la frontera cambien. Por lo tanto, aprenderemos que detectar la recesión a través de los datos del mercado laboral es más difícil de lo que pensábamos anteriormente.
Este artículo es Pascal Michaillat.



